This semester I am taking an independent study at Purdue focusing on “Binary Analysis” working through the problems provided by RPISEC in their Modern Binary Exploitation course MBE is an introduction to different types of vulnerabilities in software, and provides and easy, medium, and hard version of each vulnerability. There are also two course projects I plan to solve during my semester. The course “projects” are example CTF pwn category problems. (Harder versions of my classwork). All of the problems are 32bit elf executables for most of the course, and ASLR is enabled about halfway through the course. My goal this semester is to finish the majority of the course and provide notes/explanations for each lab on my blog. I hope this can be an opportunity for me to show what I have learned, but also keep notes for my future self.
Lab2
This lab focuses on stack overflows and basic memory exploitation. I downloaded the binaries onto my local ubuntu 18.04 machine.
Lab2C
The below code is the source for the LAB2C executable. This is a very simple buffer overflow of 15 bytes. When the set_me stack variable is filled with the correct 0xdeadbeef bytes, the shell command is executed. This was an introductory problem designed to help familiarize myself with how the compiler creates and adds values to the stack in memory. The techniques used to analyze the stack will be covered in Lab2B
|
|
Below is the python exploit I used to overflow the buffer:

The bytes are in little endian order, x86 architecture stores integers in little endian order Endianness Once executed the set_me variable is filled with the correct values and the program calls the shell() function. I print out the .pass variable to simulate the goal of the original wargame created by MBE.
General Tools/Notes
Below I want to make notes for myself and readers about useful commands/syntax/tools etc that will be helpful in future binary challenges Useful commands/syntax learned:
GDB:
|
|
FORMAT:
x/nfu [address]
- n: How many units to print (default 1)
- f: Format character (like „print“).
- u: Unit. Unit is one of:
- b: Byte
- h: Half-word (two bytes)
- w: Word (four bytes)
- g: Giant word (eight bytes)).
Peda
Peda is the tool MBE site uses and is SUPER useful for exploitation. I’ll include a few screenshots below in this part. Below are some useful commands, along with a link to more. Great List of commands for Peda
context_[stack/register/code]
xinfo register [register]
telescope [address] [#]
pattern [search\offset $pc]
stepuntil [instr]
nextcall [func] // nextjmp
hexdump [address] [count]
Other:
Converting hex to decimal for quick math checks: source To convert from decimal to hex,
|
|
Regsiter quick reference:
$pc -> register with program counter (i.e. $eip)
$sp -> register with stack pointer (i.e. $esp)
$fp -> register with pointer to stack frame (i.e. $ebp)
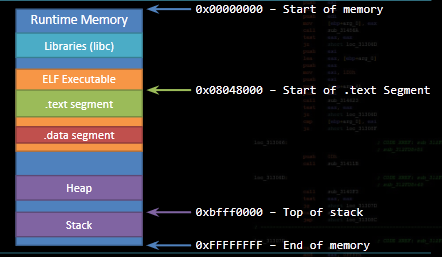
Below is an image of memory. Useful to remember stack grows up (higher -> lower), heap grows down (lower -> higher). I always seem to forget this, and I want a reminder. This is important as in new stack frames (i.e. each function call) the old eip, ebp registers are pushed first with each stack frame (i.e. higher memory addresses)
Lab2B
Below is the source code with some comments of analysis of Lab2B executable.
|
|
During debugging during the initial execution the address required to overwrite is seen in the telescope command output.
|
|
Now in order to jump to the shell function this address needs to be overwritten 27 bytes into the stack (the 28th byte is the start of the return address). Luckily PEDA makes this easy with the number of bytes on the left hand side. The address also needs to be in little endian order. Current Exploit: $(python -c ‘print 0x1B * “A” + “\xbd\x86\x04\x08” ‘)
Now, in order to use the shell function it requires a string argument (shell calls system() which expects a string), luckily there is already a exec_string variable that can be used! Using peda, the address of the exec_string variable can be printed. 0x0804a028 holds the address of the actual string, at address 0x080487d0.
|
|
Current Exploit: $(python -c ‘print 0x1B * “A” + “\xbd\x86\x04\x08” + “\xd0\x87\x04\x08”’)
Except the following issue occurs:

The issue is that the address of exec_string added right after the return address is not in the correct place! Below we see the expected address location for the address at ebp+0x8.
|
|
Printing this value reveals the expected stack address!
|
|
The address passed into the buffer overflow is 4 bytes below this address! Simply adding 4 more bytes to the exploit should put the address of the string at the right place!
|
|
Below I have the final execution of the exploit:

Lab2A
|
|
Here the goal is like all the others, overflow the return address of concatenate_first_chars and gain control of the return address. fgets will read in 16 bytes instead of the expected 10, since 0x10 is hex. This allows an overflow into i! (Only 3 bytes though, due to the last byte of the array being set to null by fgets: man fgets). This is because i is stored directly next to word_buff inside the struct. The addition of the struct also helped with overflowing the return address, since the struct pushes variables to the stack from bottom to top. (i.e. cat_buf is at the highest spot in the stack). source1 source2 This was confusing at first, but makes sense after reading the articles and analysis.
Since the check at the for loop is: locals.i != 10, this means the loop can be taken continuously if i is never equal to 10! (Which is easy with the buffer overflow). Therefore, in order to overwrite the return address properly, walk the locals.cat_pointer++ up the stack to the last byte before the return address!
Running the executable after a few inputs of 16 characters is show in the hexdump and stack printout below. This helped me see how the variables were arranged on the stack, and where the return address was located.
|
|
Above, at 0xffffd030 is the start of the word_buf variable. Then, the struct variables are all stored in the stack in increasing order. This means at 0xffffd03c is the start of i’s data, *0xffffd040 is the start of the cat_pointer’s address, 0xffffd044 is the start of cat_buff.
At offset 0xffffd05c is the return address 0x80487e6. This address is 24 bytes below the start of cat_buff ( expr $((0x5c)) - $((0x44)) = 24 ) which can be checked by printing out the disassembled main function.
|
|
So the last step is to determine the address of shell(). Which is done by printing its address.
|
|
So finally the final exploit can be run. The only time, the whole word_buf needs to be filled is during the first overflow ( "A" * 14 + "\n" ). After that, since the cat_pointer only sets itself to the value of the first character in the buffer, a single character is all that is needed( "A\n"*23 ). This puts the cat_pointer at the start of the return address. Finally, writing shell() address in little endian order, one byte at a time( "\xfd\n\x86\n\x04\n\x08\n" ). The last “\n” sent by the print function ends the for loop and the return address almost pops a shell.``
Below is the almost final execution of the exploit!

I was very confused why the shell never ran, even after I had properly executed the shell, since it printed out the winning text: “you got it”. After a little bit of googling, I came across the answer: allow input/output redirection
Using a cat command following the exploit, allows stdin to stay open for input into my shell!
